An alternative pricing model has emerged recently, largely in the cloud, that directly prices units of actual work. Examples include various managed cloud database and analytics services like Dynamo, Aurora and Redshift (Amazon), BigQuery (Google), and Azure SQL and may others. Paying for units of work using services like these is a very precise way to understand the cost of your computation.
However, managed cloud services offer only a limited selection of supported software, and workloads tend to be locked-in to specific cloud service providers.
This note explores standard machine-learning ideas for pricing compute resources in terms of units of actual work for general workloads. It’s a problem that my colleagues at Atrio and I have been thinking about for a few years.
Basic constraints
Some applications have well-specified hard requirements that must be satisfied in order to run. For instance, an app might require a specific kind of GPU, or a minimum amount of system RAM per thread, or a particular kind of CPU instruction set.
More interestingly, an app may require access to a user-specified, potentially large, data set within a specified distance from the compute resource. Here, distance might be specified by latency, bandwidth, cost to transport, or a combination of those factors.
Before thinking about sophisticated performance models, hard constraints must be applied to produce a set of feasible compute resources that a given app can run on. It’s a basic but necessary filtering step.
Factor models
A straightforward and useful approach simply measures how effectively a given application uses specific hardware factors like memory, network, storage, and various CPU resources. Describing applications in terms of utilization of specific hardware factors is nothing new. It’s generally how we decide to buy computer resources today. For instance if an application is known to run in parallel and transfer large amounts of data over a tightly coupled network, then we know to buy machines with good network fabrics like Infiniband.
Atrio has developed tools to help automate thinking about performance factors for applications. Any time a job runs through the system, users are provided with a summary report of key performance factors and how well the job used (or how badly the job mis-used) them. The report provides basic recommendations for application performance tuning, and illustrates the compatibility of the application with all available hardware resources based on the app’s performance utilization across the factors. For example, if an app is observed to use a lot of floating-point computation, but doesn’t use much vectorized floating-point instructions, the performance advice includes a recommendation to explore using vectorized libraries to get better resource utilization.
Clustering
Atrio produces a lot of performance telemetry data for every job running through the system (both in clouds and in local datacenters). Those data include things like overall system-level statistics (memory use, I/O wait times, load averages, etc.) as well as detailed performance counter information from the CPU hardware and Linux Kernel. (All of the raw performance data and a high-level summary report are easily available to users.)
Instead of considering just a few specific performance factors, we can use standard machine learning tools to cluster all applications on a given hardware resource based on all their performance data. For instance the following network visualization shows clusters of a few Parsec and other benchmarks run on an Amazon AWS C5 instance type. (The repeated names correspond to different runs of the same app.)
A new application can be placed in a cluster of peers after at least one run on a specific system. The clustering is based on observed resource utilization. Once that happens, we can make an educated guess as to how that same application will perform across a large set of diverse hardware resources based on historical performance data for the cluster as a whole. For instance, given a new app run on a cloud instance somewhere, the idea is to estimate if it can run more efficiently on other cloud instance types across all cloud service providers–or even across local compute resources or other systems like supercomputers.
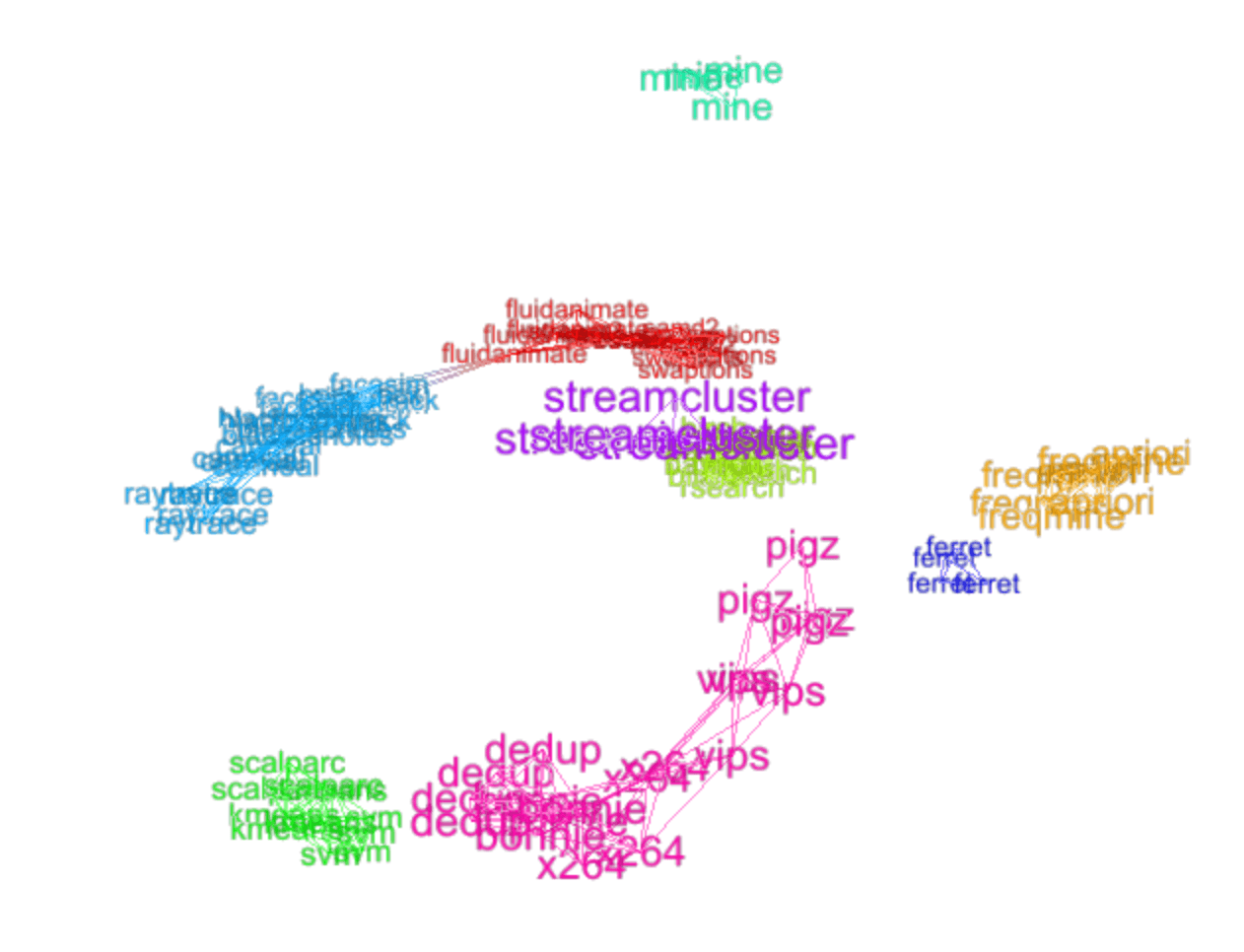
Despite the use of machine learning and statistics, the idea is very simple. Intuitively, molecular dynamics apps (for example) will tend to perform similarly to other molecular dynamics apps and work best on similar types of computer hardware. Ditto for other kinds of related workloads.
Instead of making a comparison based only on the class of a given application, we cluster apps based on their measured performance utilization data. What I’m calling an “app” here is really an application instance (aka job) made of a program together with input data and parameterization. Profiling apps based on observed performance telemetry instead of simply application category admits a finer-grained characterization and prediction of relative performance across many kinds of compute resources.
Recommendation engines
A related approach to clustering treats workload pricing problem as a basic recommendation problem. Consider a table of integer ratings between 1 (best) and 5 (worst) of all application job runs along rows and all possible hardware compute resources along columns. Purely hypothetically for example:
| Compute resource | ||||
|---|---|---|---|---|
| Job | Amazon C5 | UCSD Cosoms | Azure H16r | … |
| Bowtie genomics job 1 | 2 | 1 | … | |
| Bowtie genomics job 2 | 1 | 3 | … | |
| Black Scholes pricing job 1 | 5 | 3 | … | |
| OpenFOAM CFD job 1 | 2 | 1 | 1 | … |
| OpenFOAM CFD job 2 | 1 | … | ||
| … | … | … | … | … |
Of course, not every job runs on every compute resource so the table is sparse and consists mostly of missing entries. The classic recommendation engine problem fills in the missing entries with estimated rankings by a systematic process. It’s like the Netflix problem (a table of movies by viewer rankings) or e-commerce product recommendation.
In our case, we have a lot of extra information about each job (all the measured telemetry data and other job information), as well as lots of extra information about each compute resource, often called the recommendation problem with side information. Our situation contains many additional complications, however (the kinds of extra information may vary by compute resource, the telemetry measurements are noisy and may be incomplete, etc.). Despite the complications the general idea is still a basic recommendation problem: given a very sparse collection of resource rankings for every app and every resource, fill in the blanks to predict the unknown rankings.
Predicted rankings can then be combined with cost and other information to provide an estimate of performance and cost across all resource for all apps. Like most machine learning solutions, the predictions are refined over time as more data observations become available.
Atrio performance modeling
We combine all these ideas to provide reasonable estimates of performance for applications across all resources:
We carefully monitor detailed performance telemetry statistics of every job, and make that raw data available.
Raw data are summarized in reports that break down performance utilization by specific hardware resource factors (CPU/disk/vectorization/etc.) and indicate general compatibility with available systems.
Resource utilization is also summarized in a high-level performance advisor report that highlights potential under-utilization and advice for mitigating problems.
We use simple machine learning techniques to produce estimates of performance of any app on any compatible system for well-informed price/performance assessments.